Friendli Engine
About Friendli Engine
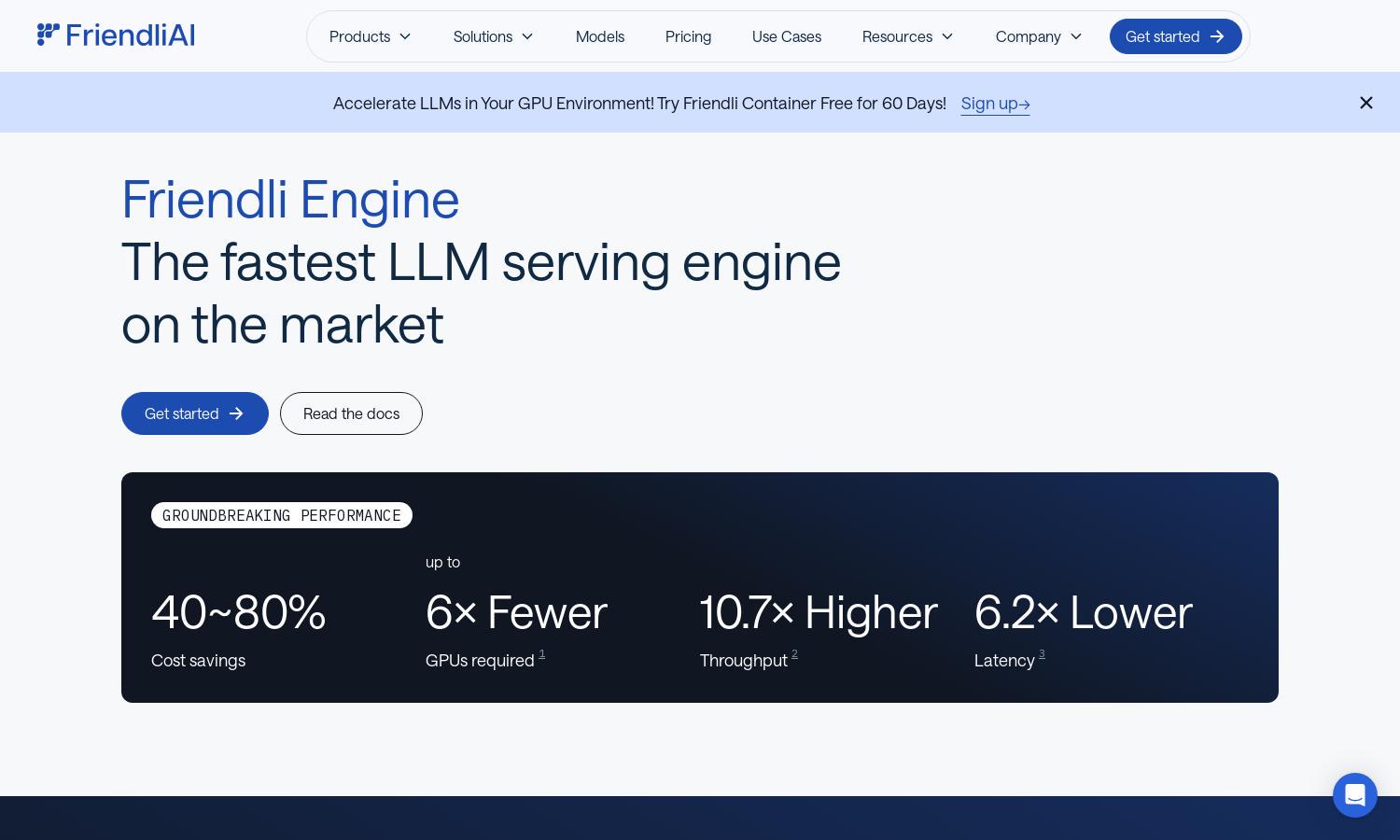
Friendli Engine is a leading solution for developers seeking fast and cost-effective LLM inference. With innovative features like iteration batching and speculative decoding, it significantly enhances performance while reducing hardware requirements. Perfect for businesses looking to streamline AI model deployment, Friendli Engine delivers groundbreaking efficiency.
Friendli Engine offers flexible pricing plans, including a free trial for new users, and scalable options to suit individual or enterprise needs. Each plan provides unique resources, with cost-effectiveness increasing as you upgrade, ultimately securing greater savings and performance benefits using powerful AI models.
The user interface of Friendli Engine is designed with simplicity and efficiency in mind. Its intuitive layout ensures seamless navigation, enabling users to access key features without hassle. Unique tools, including dashboards for monitoring performance, enhance the browsing experience and empower efficient AI model management.
How Friendli Engine works
Users interact with Friendli Engine by signing up and selecting their preferred LLMs for deployment. After an easy onboarding process, users can quickly navigate through features like dedicated endpoints, containers, and serverless options to optimize generative AI model performance. The platform's user-friendly design enhances each interaction, ensuring maximum efficiency.
Key Features for Friendli Engine
Multi-LoRA Serving
Multi-LoRA serving is a standout feature of Friendli Engine, enabling simultaneous use of multiple LoRA models on fewer GPUs. This innovation streamlines LLM customization, making it easier and more efficient for developers to tailor generative AI applications.
Iteration Batching
Iteration batching is a revolutionary technology implemented by Friendli Engine that significantly boosts LLM inference throughput. By managing concurrent generation requests efficiently, it ensures latency requirements are met while optimizing performance, allowing users to effectively scale their AI operations.
Friendli TCache
Friendli TCache is a unique optimization feature of Friendli Engine that intelligently stores frequently used computational results. By reusing these cached results, it drastically reduces GPU workload and improves processing times, providing users with faster inference capabilities and enhanced efficiency.