Velvet
About Velvet
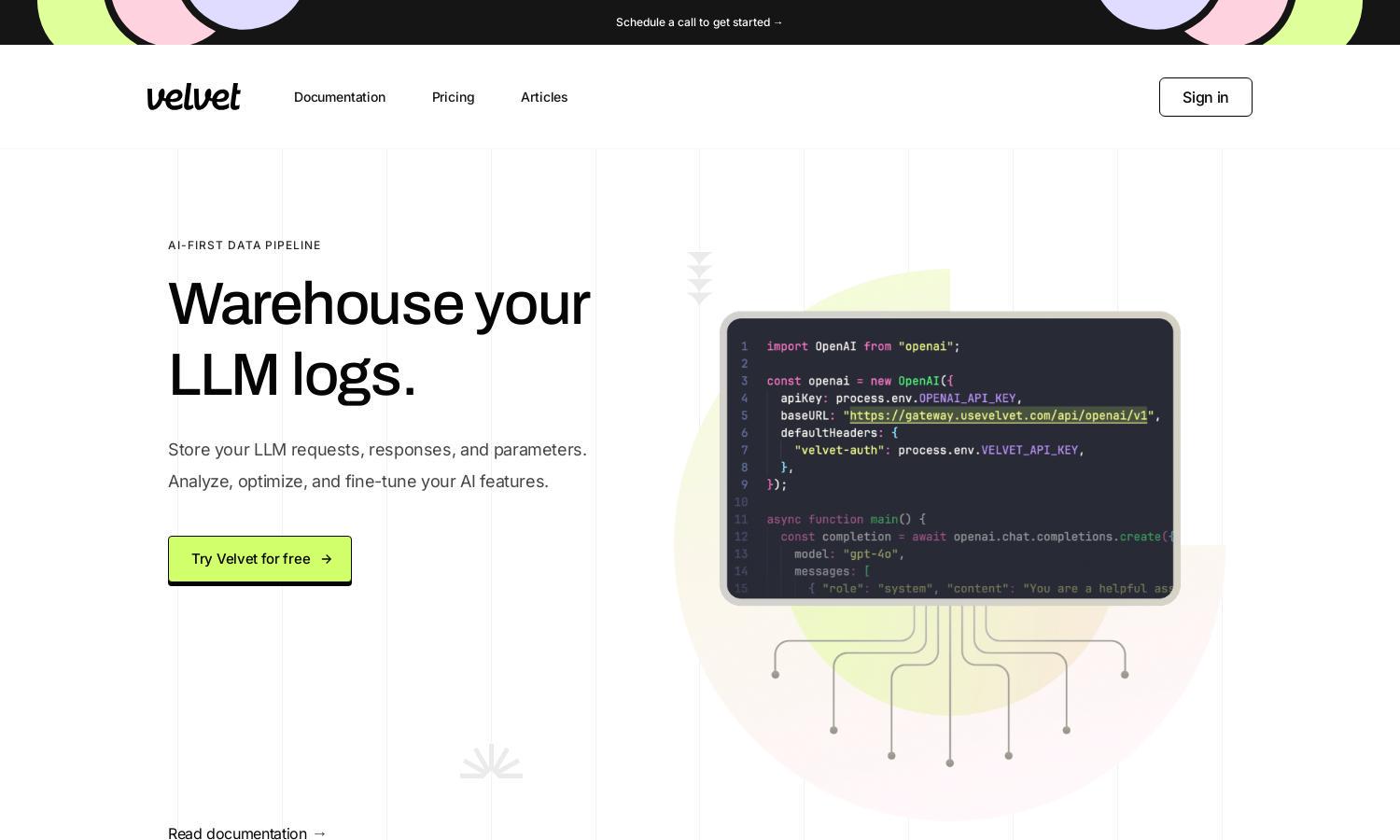
Velvet is an innovative AI gateway for engineers, streamlining database request logging and feature optimization. By using just two lines of code, users can efficiently analyze usage, run experiments, and tackle AI-related challenges seamlessly. Velvet empowers engineering teams to enhance their AI operations effectively.
Velvet offers a free tier allowing up to 10k requests per month, enabling users to explore its features without commitment. As users progress, they can access premium features that increase data handling capacity and enhance optimization tools, making Velvet a valuable investment for engineering teams.
Velvet features an intuitive user interface designed for seamless navigation. Its clean layout enables users to access essential tools easily, while practical features enhance the browsing experience. The user-friendly design of Velvet encourages efficient data analysis and feature optimization for AI applications.
How Velvet works
Users begin by creating an account on Velvet and following the straightforward onboarding process. They set their base URL to the Velvet gateway and connect their database, allowing them to log requests. With just two lines of code, users can execute features like caching and analysis, optimizing their AI capabilities seamlessly.
Key Features for Velvet
Request Logging
Velvet's request logging feature allows users to warehouse every API request to their PostgreSQL database, optimizing AI operations. By gaining valuable insights from these logs, users can analyze usage patterns and enhance AI feature performance while ensuring data compliance and security.
Experiment Framework
The experiment framework in Velvet enables engineers to run tests on various datasets to fine-tune models effectively. Users can leverage this feature to select specific datasets, run continuous experiments, and improve AI outputs, maximizing their overall efficiency in model development.
Intelligent Caching
Velvet incorporates intelligent caching, significantly reducing both costs and latency for API requests. This unique feature allows users to streamline operations by minimizing redundant calls, ensuring faster response times, and optimizing resource allocation for their AI-driven applications.
You may also like: