DeepRails
DeepRails instantly detects and fixes AI hallucinations before they reach your users.
About DeepRails
DeepRails is the definitive kill-switch for AI hallucinations, engineered for developers and engineering teams who refuse to ship unreliable AI. In an era where large language models power everything from customer support to legal research, fabricated facts and inconsistent reasoning remain the biggest barrier to trustworthy, production-grade adoption. DeepRails confronts this challenge head-on as a comprehensive AI reliability and guardrails platform. It doesn't just passively monitor; it actively defends your application's integrity by hyper-accurately evaluating AI outputs for factual correctness, grounding, and reasoning consistency. This enables teams to distinguish critical errors from benign model variance with unprecedented precision. More importantly, it provides the tools to substantively fix these hallucinations in real-time through automated remediation workflows before flawed outputs ever reach an end-user. Built to be model-agnostic and production-ready, DeepRails integrates seamlessly with leading LLM providers and modern dev pipelines. It offers custom evaluation metrics, human-in-the-loop feedback systems, and full auditability. This is the essential toolkit for engineering teams committed to deploying AI systems they can genuinely stand behind, finally making trustworthy AI a deployable reality.
Features of DeepRails
Defend API - Real-Time Correction Engine
The Defend API is your proactive shield against flawed AI outputs. It acts as a real-time correction engine that sits between your LLM and your end-user. The API automatically scores model outputs against configured guardrail metrics like factual correctness and instruction adherence. When a potential hallucination or quality issue is detected, it can trigger automated remediation actions like "FixIt" or "ReGen" to correct the output on the fly before it's delivered. This ensures only vetted, high-quality responses reach your customers, turning a passive monitoring tool into an active defense system.
Expansive & Custom Guardrail Metrics
DeepRails provides an expansive library of pre-built, ultra-accurate guardrail metrics tailored for production AI. Choose from general-purpose metrics like Correctness, Completeness, and Context Adherence, or create custom metrics for your specific domain. Each metric delivers granular 0-100 scores, with DeepRails boasting significant accuracy advantages over alternatives like AWS Bedrock. This library allows you to precisely detect everything from factual inaccuracies and safety violations to agentic performance issues, giving you surgical control over AI quality.
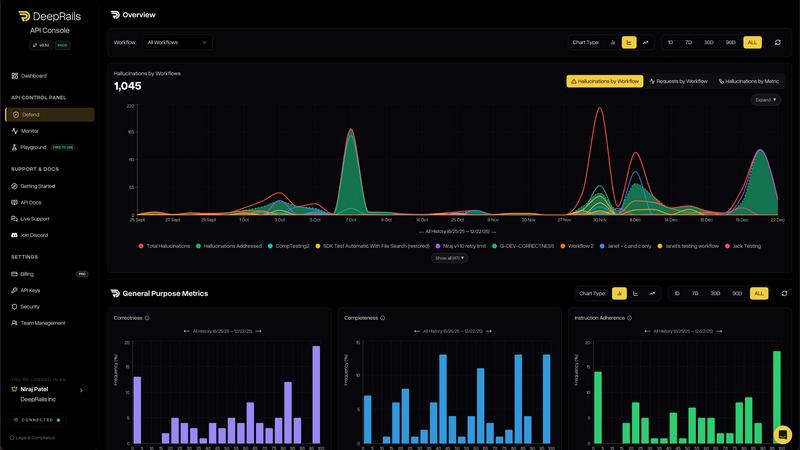
Full Auditability & Analytics Console
Every interaction processed by DeepRails is logged in real-time, providing complete transparency. The DeepRails Console offers beautiful metrics, detailed traces, and full audit logs for every run. You can track performance trends, monitor key guardrail scores, and drill down into any individual interaction to see the complete improvement chain—from the original LLM output through DeepRails' evaluation and any remediation steps taken. This audit trail is critical for debugging, compliance, and continuously improving your AI systems.
Seamless Integration & SDKs
Built for engineers, DeepRails is designed for seamless integration into existing workflows. It is model-agnostic, working with any leading LLM provider. Comprehensive SDKs and a straightforward API allow you to integrate the Defend and Monitor APIs into your production pipeline in minutes. The platform fits naturally into modern development cycles, enabling you to implement robust AI guardrails without overhauling your entire architecture, making advanced reliability accessible to every team.
Use Cases of DeepRails
Legal & Compliance Research
In legal domains, hallucinated case citations or incorrect statutory interpretations can have severe consequences. DeepRails ensures AI-powered legal assistants and research tools provide factually accurate information. By using the Correctness and Context Adherence metrics, it verifies that every legal citation is real and that all advice is grounded solely in the provided case documents, preventing costly errors and maintaining rigorous compliance standards.
Financial Advisory & Reporting
Financial AI tools must provide perfectly accurate data regarding market figures, company earnings, or investment advice. DeepRails guards these applications by evaluating outputs for factual correctness and completeness. It can automatically correct misstated percentages or hallucinated financial data before a report is generated for a client, ensuring unwavering reliability in a sector where trust is paramount.
Healthcare Information & Triage
AI chatbots in healthcare must avoid dangerous inaccuracies regarding symptoms, drug interactions, or treatment advice. DeepRails' safety and correctness metrics act as a critical safeguard. It can detect and filter out unverified or potentially harmful medical information, ensuring that patient-facing AI only delivers content that is safe, grounded in provided medical context, and factually sound.
Customer Support & RAG Systems
For Retrieval-Augmented Generation (RAG) systems powering customer support, it's vital that answers are drawn solely from the provided knowledge base. DeepRails' Context Adherence metric is essential here, evaluating whether each claim in the AI's response is directly supported by the source documents. This prevents the AI from "going rogue" and inventing product features or support policies, maintaining brand integrity and customer trust.
Frequently Asked Questions
How does DeepRails differ from basic LLM output filtering?
Basic filtering often relies on simple keyword blocking or sentiment analysis. DeepRails goes far deeper, employing advanced evaluation models to assess the factual accuracy, reasoning consistency, and contextual grounding of an AI's response. It doesn't just flag profanity; it detects subtle factual hallucinations, scores them on a precise scale, and can automatically trigger complex remediation workflows to fix the issue, offering a proactive quality control system rather than a passive filter.
Can DeepRails work with any LLM or AI model?
Yes, DeepRails is fundamentally model-agnostic. It is designed as a platform that sits in your inference pipeline, evaluating the text output from any model—whether it's from OpenAI, Anthropic, Google, open-source models, or your own fine-tuned variant. You can seamlessly integrate its APIs to add a layer of reliability and guardrails regardless of your underlying model provider.
What does "automated remediation" or "FixIt" mean?
When DeepRails detects an issue that crosses a defined threshold, it can take automated action. "FixIt" might involve prompting the same LLM with the original query plus the evaluation rationale, guiding it to produce a corrected answer. "ReGen" could involve switching to a more reliable model for that specific query. These actions happen in milliseconds within the API call, fixing hallucinations before the response is sent to your user, all documented in the audit log.
Is DeepRails suitable for evaluating autonomous AI agents?
Absolutely. Beyond single-turn responses, DeepRails offers metrics for Agentic Performance, designed to evaluate how effectively an AI autonomously plans, decides, and executes complex multi-step tasks. This allows teams to monitor the reliability and effectiveness of entire AI workflows and agentic systems, ensuring they remain on track and produce trustworthy end results.